CPNAV: Calibrated Vision-Language Navigation for Object-Goal Search in Unseen Environments
Qizhao Chen, Yuanhong Zeng, Shoh Nishino, and Anushri Dixit
Abstract
Directing a robot to locate a target object in unseen environments remains a central challenge in embodied AI. Vision–Language Model (VLM)–based methods provide rich semantic reasoning but often produce uncalibrated and overconfident action decisions. We introduce CPNAV, a navi- gation framework that combines collision-aware planning with statistically calibrated VLM action scoring for map-free object- goal navigation. From RGB-D input, CPNAV constructs a navigability map, generates collision-free motion primitives, and queries two VLMs for goal detection and action scoring. The resulting scores are calibrated offline via conformal prediction (CP) using oracle actions obtained from a modified tree search, providing finite-sample guarantees at a user-specified risk level. The CP layer is model-agnostic and can wrap any VLM policy. Online, the calibrated threshold prunes the search tree by filtering unreliable actions with backtracking. Experiments on the HM3D object-goal navigation benchmark show that CPNAV improves over the 4 Lets look at the main problem of the baseline uncalibrated method. The agent is placed at a random location in an apartment, the goal is to find the plant a baseline in both reliability and efficiency. In simulation, the proposed method achieves a relative improvement of 6.17% in the success rate and 11.34% in the success weighted by path length (SPL) compared to the non-calibrated baselines. In real- world deployment on a modified Hiwonder MentorPi robot, CPNAV achieves relative improvements of 24.99% in Success Rate and 15.20% in SPL compared to baselines.
Method
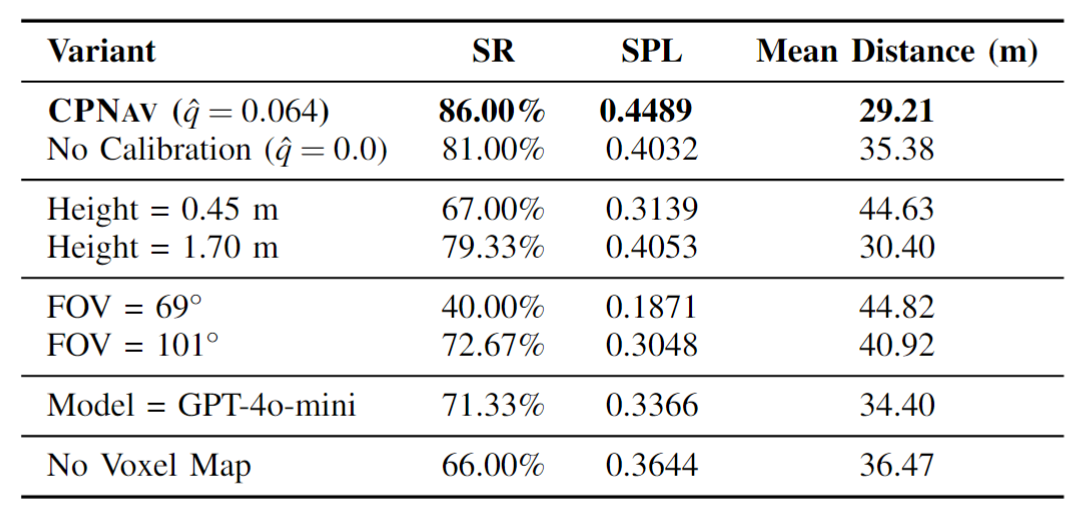
Our idea in CPNAV is to make vision-language navigation more reliable by combining three components: VLM action scoring, conformal prediction for calibrated safety sets, and backtracking tree search. From RGB-D observations, the robot proposes collision-free actions, scores them with VLMs, filters unreliable choices using a conformal threshold, and then explores the remaining actions in a search tree.
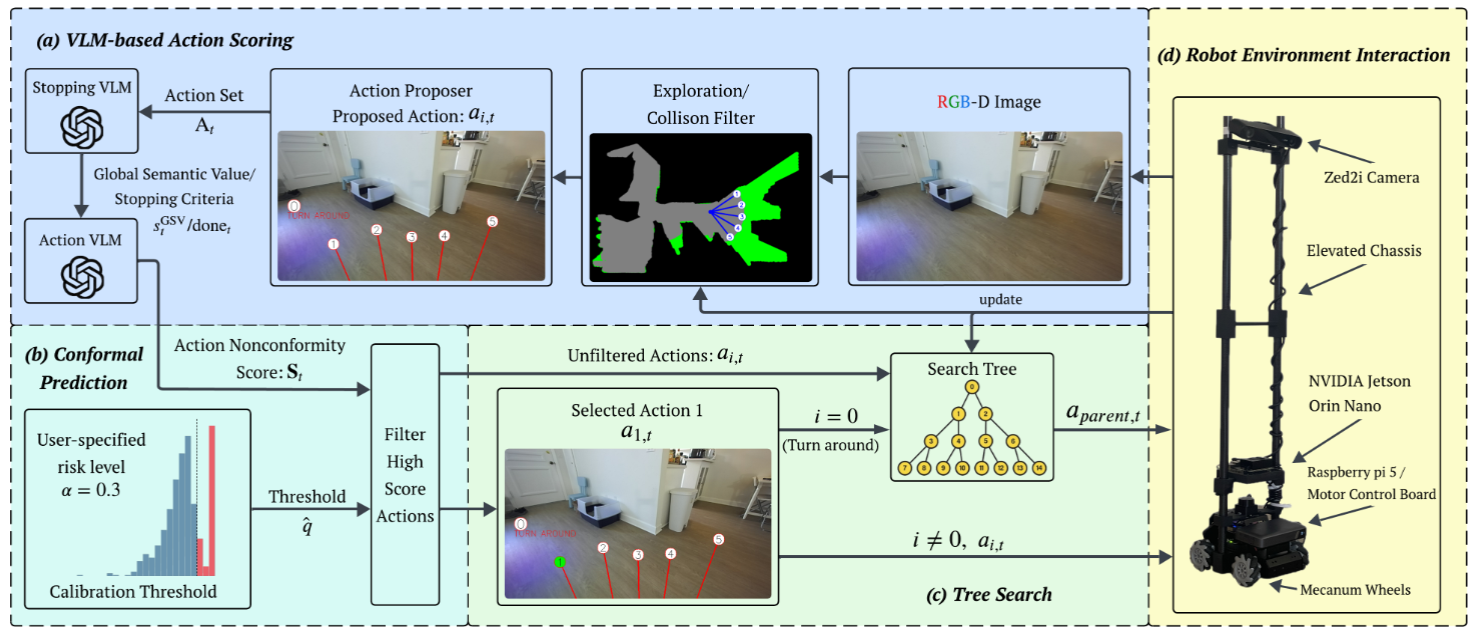
(a) VLM-Based Action Scoring
From the RGB-D image, CPNAV first builds a local navigability representation and generates collision-free executable actions. These proposed actions are projected back onto the camera image using the camera intrinsics, so the VLM can reason about concrete choices in the scene. At the same time, the robot records a voxel map that marks explored space and obstacles, helping the action proposer prioritize unexplored regions while enforcing collision safety.
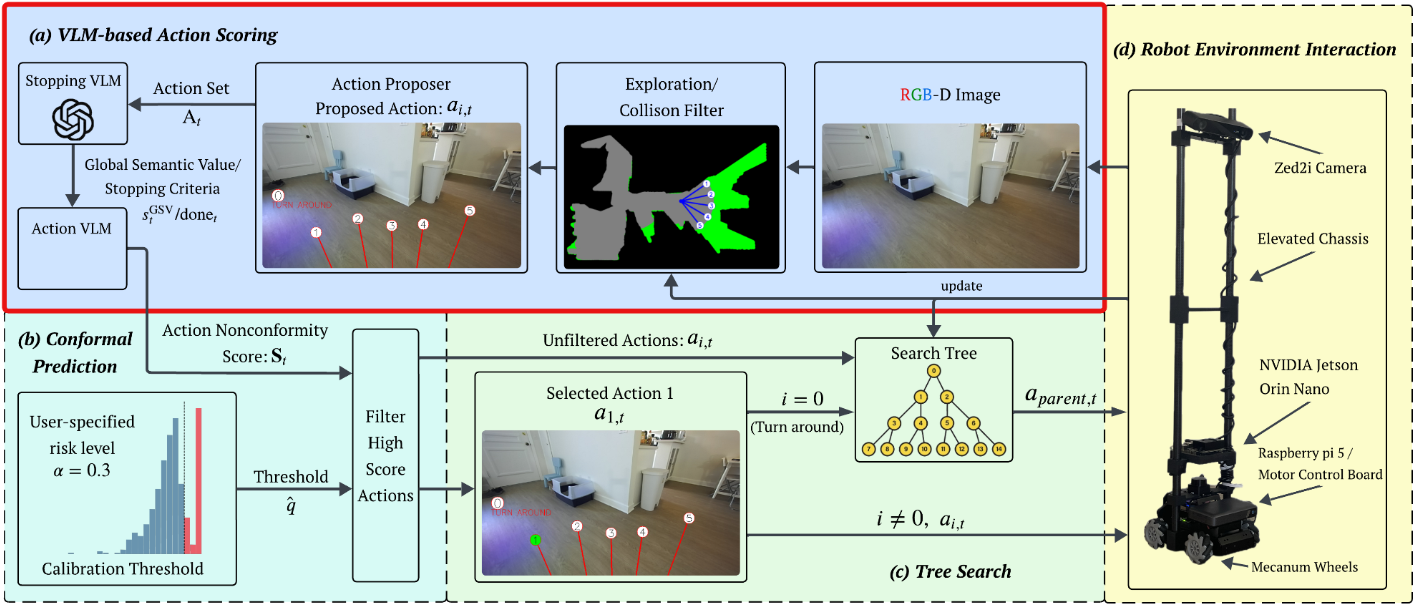
(b) Conformal Prediction
The conformal prediction layer calibrates the VLM action scores using an offline calibration set and a user-specified risk level. At runtime, CPNAV filters out actions whose confidence falls below the calibrated threshold, keeping only statistically reliable actions. This calibrated safety set is designed so that, with high probability, the oracle/correct action is not removed during navigation.
(c) Backtracking Tree Search
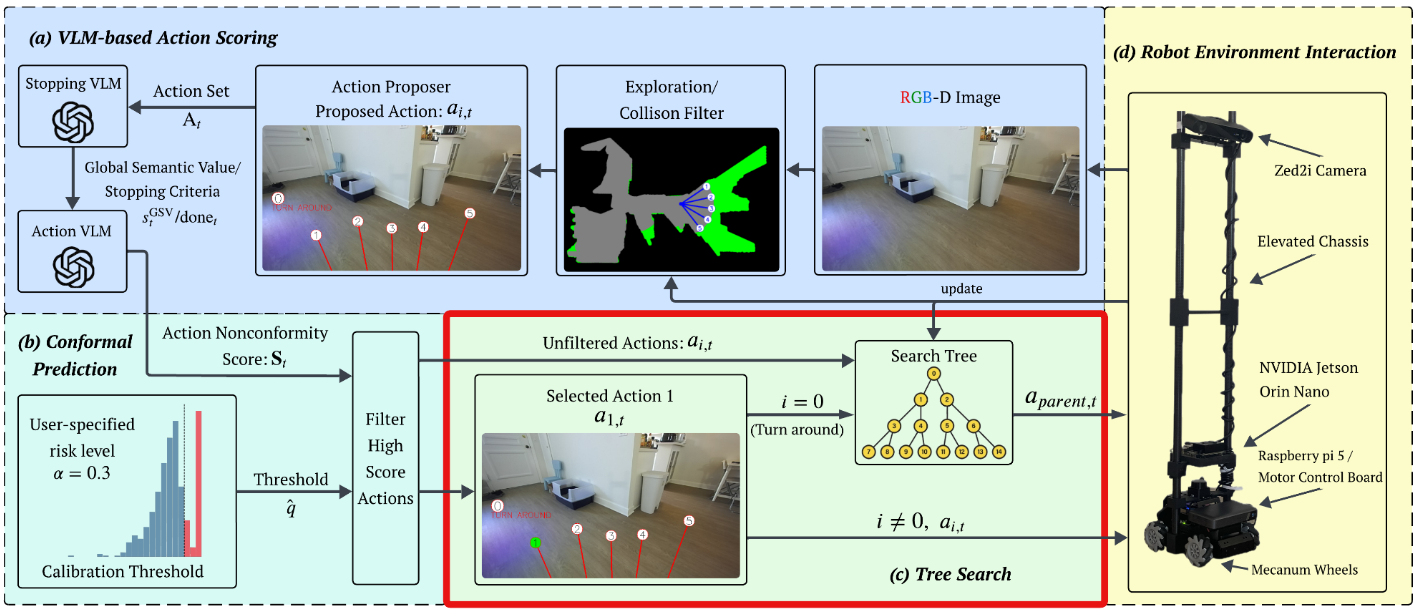
After conformal filtering, the remaining admissible actions are explored in a BFS-style search tree. Each node represents a visited robot state, and each edge represents an executable action from that state. If the selected action is a turn-around or backtracking command, the robot returns to a parent node and continues expanding untried admissible actions, reducing wasted exploration while preserving a path toward the goal.
(d) Robot Environment Interaction
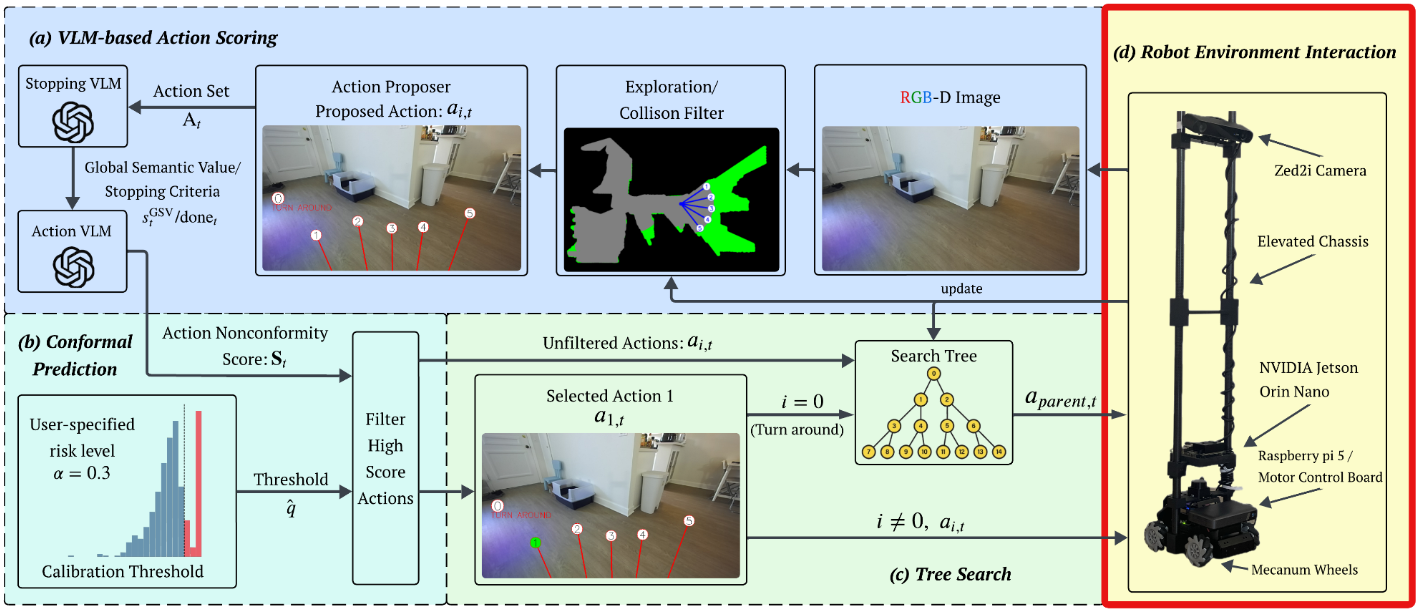
CPNAV is evaluated in simulation using AI Habitat with the HM3D dataset, and validated in the real world on a modified Hiwonder MentorPi M1 robot. The hardware platform uses a ZED 2i stereo camera for RGB-D perception, a Mecanum drivetrain for omnidirectional motion, and onboard compute/control hardware for deployment.
Experiments
Simulation Experiments
The simulation experiments are formulated as object-goal navigation episodes in AI Habitat with the HM3D dataset. The agent starts in an unseen indoor scene and must find the target object within a fixed step budget. The paper evaluates success rate (SR), success weighted by path length (SPL), shorter-horizon success/SPL under 50 and 100 steps, and mean travel distance.
CPNAV is compared against four alternatives: Simple Set, Ensemble Set, Prompt Set, and No Calibration. The first three are alternative action-set construction strategies, while No Calibration keeps the same navigation pipeline without the conformal prediction threshold. CPNAV uses the calibrated threshold reported in the paper and achieves the best SR, SPL, short-horizon metrics, and mean distance among the compared policies.

Hardware Experiments
Following the hardware setup described in the paper, CPNAV was evaluated on a modified Hiwonder MentorPi M1 mobile robot with a Mecanum drivetrain for omnidirectional motion. State estimation used SLAM Toolbox by fusing a 2D LiDAR scanner, wheel odometry, and an IMU, while a ZED 2i stereo camera provided rectified RGB-D observations for perception. The paper reports 24 randomized object-goal episodes across two residential apartment layouts, comparing the uncalibrated baseline against CPNAV with a calibrated threshold.
The hardware rollouts below compare the baseline and CPNAV in the same object-goal navigation setting. The baseline commits to less reliable branches, exceeds the maximum step limit, and fails to reach the goal. CPNAV uses calibrated VLM scores to choose more reliable actions and reaches the goal in 14 steps.


In these hardware trials, CPNAV improves the robot’s reliability and path efficiency by pruning low-confidence branches during exploration. The reported success rate increases from 66.67% to 83.33%, SPL improves from 0.4204 to 0.4843, and mean distance traveled decreases from 9.0330 m to 6.2949 m.

Search Tree Efficiency
These offline tree visualizations show the same experiment as the hardware GIFs above, but as search trees. The baseline explores a broader and more diffuse tree, expanding several low-value branches before exceeding the step limit. CPNAV uses conformal prediction to calibrate vision-language action scores, so unreliable actions can be filtered during tree search. The resulting tree is more focused: fewer branches are explored, and the search progresses more directly toward the goal.
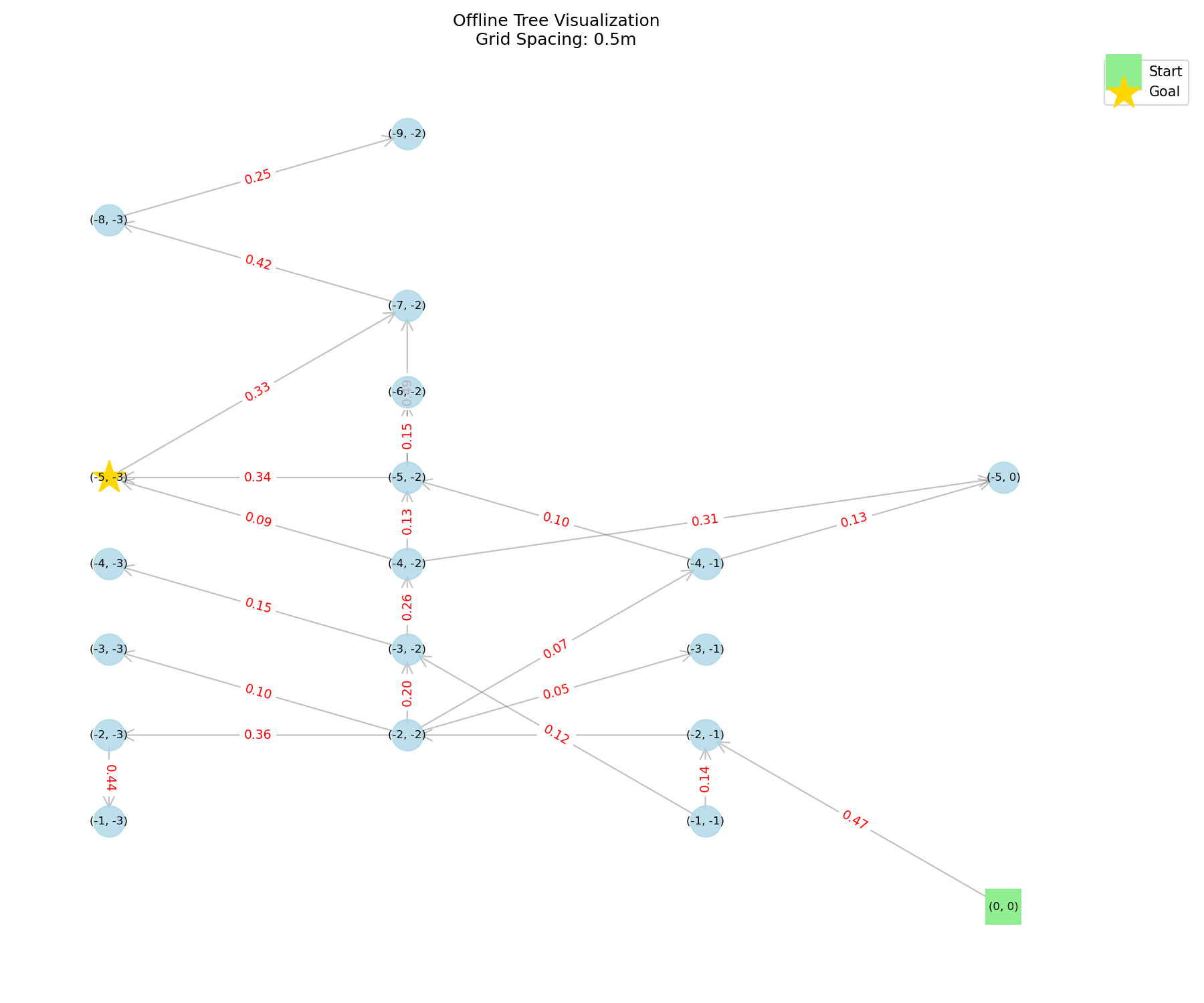
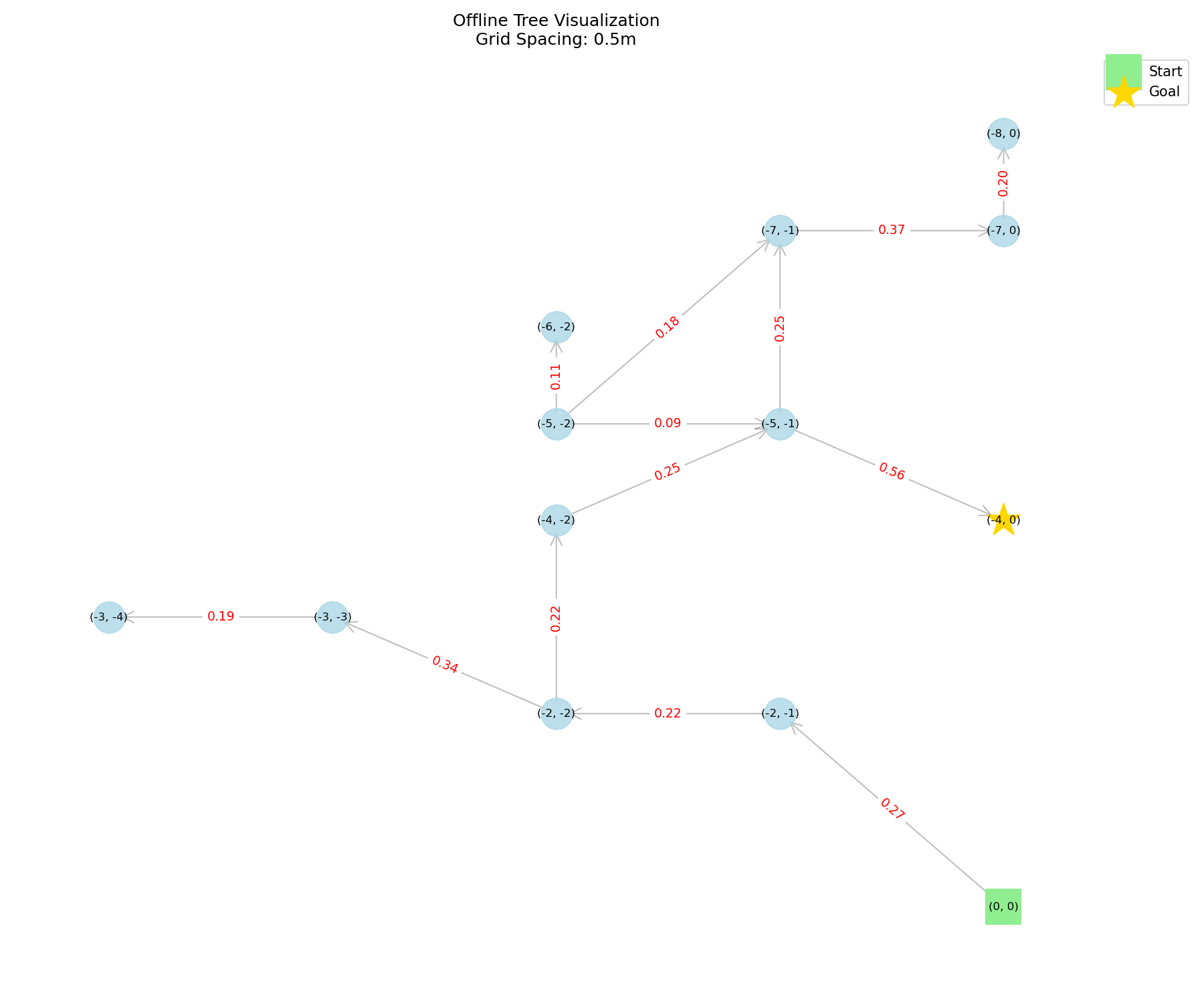
Sensitivity Study
The paper also studies how CPNAV changes under sensing and modeling variations. This includes camera height, camera field of view, the VLM model used for action scoring, and whether the voxel map is included. The study shows that sensing geometry and model capacity matter: lower field of view, less informative camera placement, a smaller VLM, or removing the voxel map all reduce reliability or path efficiency. CPNAV remains the strongest configuration, indicating that conformal calibration works best when paired with informative RGB-D perception and the voxel map used by the action proposer.