Risk-Aware Reinforcement Learning with Bandit-Based Adaptation for Quadrupedal Locomotion
University of California, Los Angeles
Video
Abstract
In this work, we study risk-aware reinforcement learning for quadrupedal locomotion. Our approach trains a family of risk-conditioned policies using a Conditional Value-at-Risk (CVaR) constrained policy optimization technique that provides improved stability and sample efficiency. At deployment, we adaptively select the best performing policy from the family of policies using a multi-armed bandit framework that uses only observed episodic returns, without any privileged environment information, and adapts to unknown conditions on the fly. Hence, we train quadrupedal locomotion policies at various levels of robustness using CVaR and adaptively select the desired level of robustness online to ensure performance in unknown environments. We evaluate our method in simulation across eight unseen settings (by changing dynamics, contacts, sensing noise, and terrain) and on a Unitree Go2 robot in previously unseen terrains. Our risk-aware policy attains nearly twice the mean and tail performance in unseen environments compared to other baselines and our bandit-based adaptation selects the best-performing risk-aware policy in unknown terrain within two minutes of operation.
Methodology
We train multiple policies using CVaR-constrained policy optimization, where each critic focuses on a different tail of the return distribution, resulting in policies with varying levels of risk awareness. An upper confidence bound (UCB) bandit is then used to adaptively select the appropriate risk level online. The bandit selects the best performing policy over time as the robot interacts with the environment repeatedly.
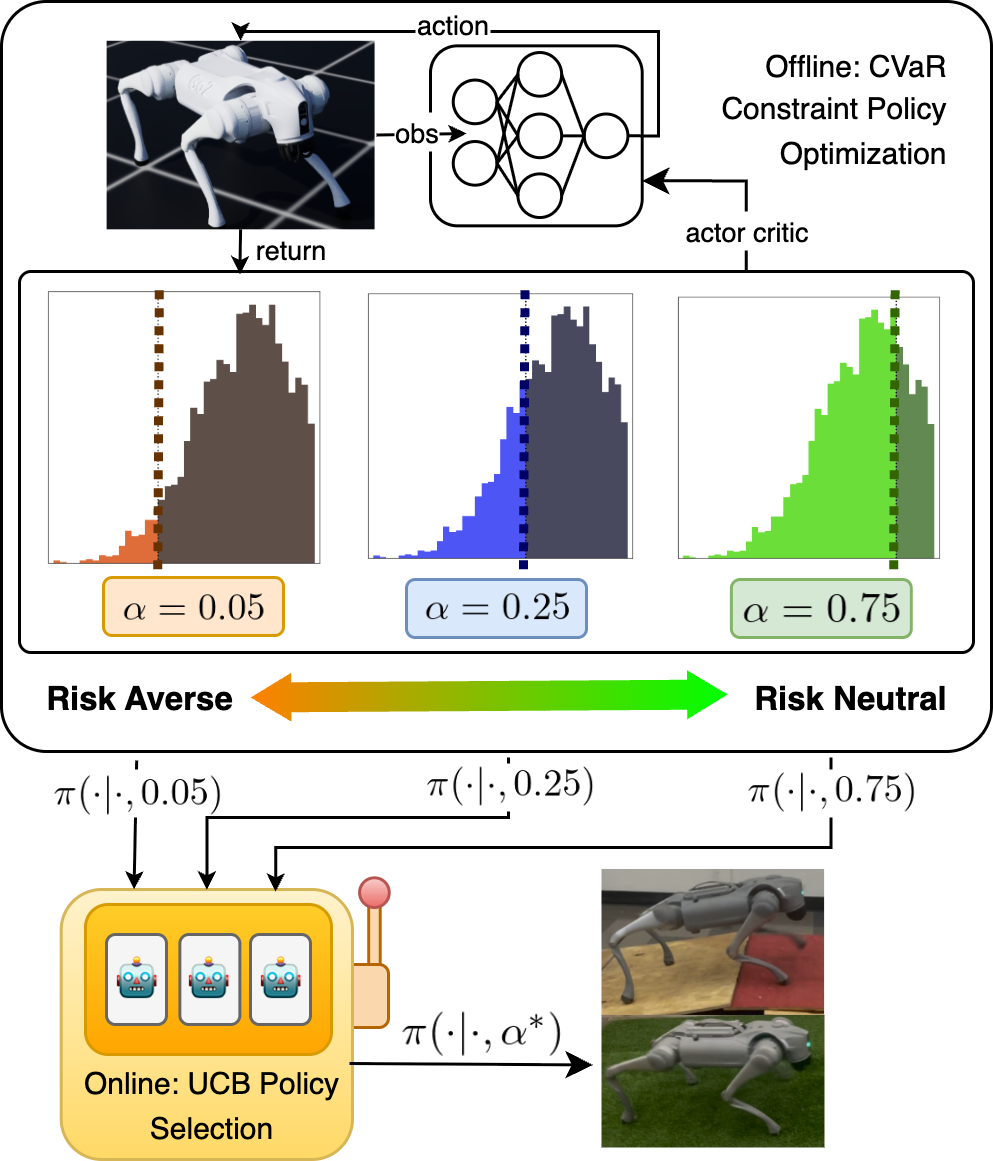
Results
Risk Awareness
We commanded the robot to walk at full speed ($v=1\,\text{m/s}$) on both ramp and grass terrains. The $\alpha=0.05$ policy did not advance despite forward commands, either when climbing the ramp or when a foot became trapped in a soccer cone hidden beneath the grass. In contrast, the $\alpha=0.25$ policy adapted a stable gait with larger steps, enabling the robot to step over hidden cones. The PPO baseline moved faster but was more prone to losing balance, particularly when descending the ramp or when one of its feet hits the soccer cone.

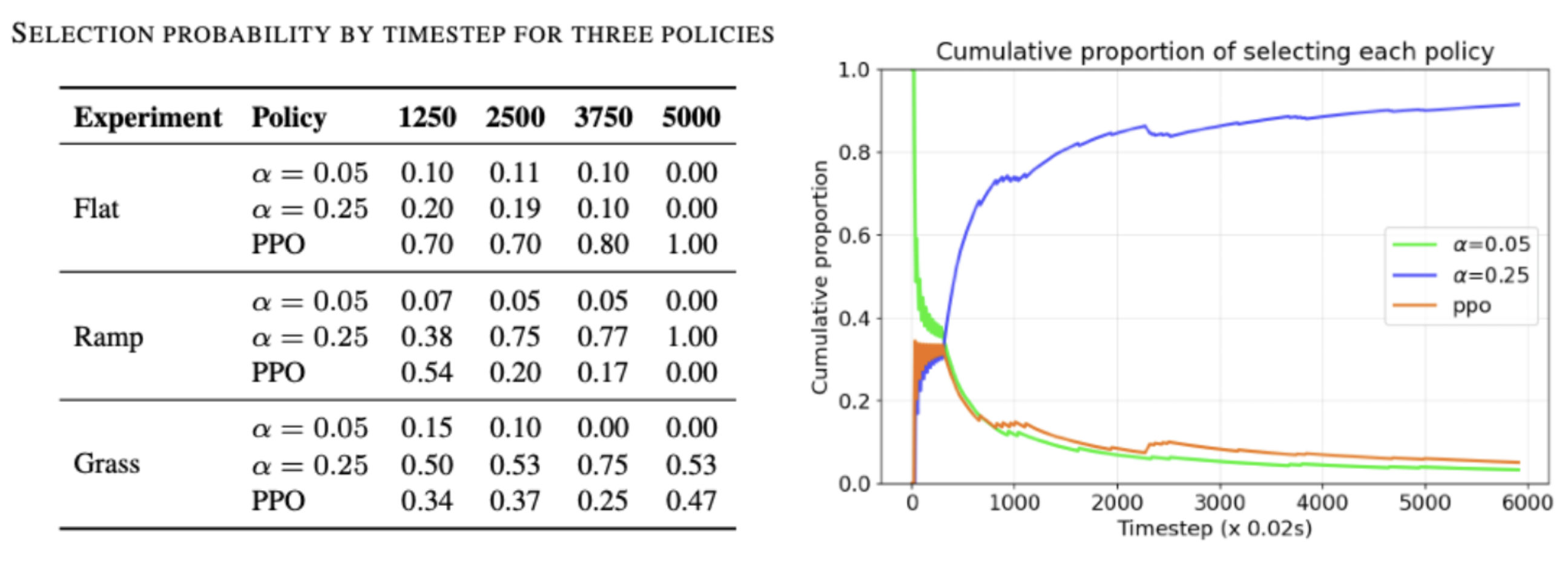
Bandit Selection
Cumulative probability of selecting each policy in one ramp experiment. Selection of the policy with $\alpha = 0.25$ quickly dominates after 2000 timesteps, which is roughly 1 minute wall clock time.
BibTeX
@article{zeng2025risk,
title={Risk-Aware Reinforcement Learning with Bandit-Based Adaptation for Quadrupedal Locomotion},
author={Zeng, Yuanhong and Dixit, Anushri},
journal={2026 IEEE International Conference in Robotics and Automation (ICRA)},
year={2026},
}